1. 为什么需要有这个,意义在哪里
日志就是计算机系统、设备、软件等在某种情况下记录的信息。具体的内容取决于日志的来源。
- 为什么需要日志系统?
从开发角度来看:程序出现问题,发现不了问题可能的原因是很令人受挫的。从运维角度来看:运维占用了大部分的软件生命周期,运维基本上是靠日志来判断问题,解决问题。从安全角度来看:安全产品的零散性、海量数据带来的效率低下、日志格式不统一、国家法律法规要求都迫使一套成功的软件需要做好日志系统。日志会成为在事故发生后查明“发生了什么”的一个很好的“取证”信息来源。
其意义在于——日志系统是一种不可或缺的跟踪调试工具,特别是在任何无人职守的后台程序以及那些没有跟踪调试环境的系统中有着广泛的应用。日志系统作为一种应用程序服务,对于跟踪调试、程序状态记录、崩溃数据恢复都有非常现实的意义。IT管理人员可以了解系统的运行状况,安全状况,甚至是运营的状况。比如:
- 为系统进行排错,优化系统的性能,或者根据这些信息调整系统的行为。
- 在安全领域,日志可以反应出很多的安全攻击行为,比如登录错误,异常访问等。
- 记录网络中所发生事件的信息,包括性能信息、故障检测和入侵检测。
- 对业务分析也是非常重要的,比如一个网站,网站的历史访问情况,新增访问情况,哪些页面访问最多等等。
为什么需要对日志系统设计和规范?
日志用来记录用户操作、系统运行状态等,是一个系统的重要组成部分。然而由于日志并非系统核心功能,通常情况下并不受团队的重视。在出现问题需要通过日志来定位时,才发现日志还存在很多问题。
日志记录的好坏直接关系到系统出现问题时定位的速度,同时可以通过对日志的观察和分析,提前发现系统可能的风险,避免线上事故的发生。使用日志我们希望能达到以下目标:
- 对程序运行情况的记录和监控;
- 在必要时可详细了解程序内部的运行状态、运行性能指标;
- 对系统性能的影响尽量小;
- 通过分析,提高系统质量和提升系统性能
2. 日志系统的设计、规范
2.1 日志分类
#####2.1.1 从存储和产生阶段,日志基本分为两类:
- 业务/运行日志_BusinessLog
记录业务系统运行情况:启动时间,运行时长,结束时间、运行结果(成功、失败等),基本描述信息。相关的信息要保存到业务日志文件中。
- 调试/异常日志_DebugLog
在系统编码过程中,方便系统查找原因,输出相关的日志信息,方便查找问题,可以不需要输出到文件,在系统业务运行过程中不记录相关问题。
#####2.1.2 从功能来说,可分为诊断日志、统计日志、审计日志三类:
诊断日志, 典型的有:
>
请求入口和出口
外部服务调用和返回
资源消耗操作: 打开文件等
容错行为: 譬如云硬盘的副本修复操作
程序异常: 譬如数据库无法连接
后台操作:清理程序
启动、关闭、配置加载
抛出异常时,记录日志统计日志:
>
用户访问统计
计费日志(如记录用户使用的网络资源或磁盘占用,格式较为严格,便于统计)审计日志:
>
管理操作
将不同需求的日志记入到不同的日志文件中,可以方便相关问题(管理平台操作审计,用户操作计费等)的处理。针对每一种需求,需要对日志的格式,日志记录的内容等进行特别的记录。
其中诊断日志还可以细分记录到不同的日志文件中,如:
Jdk类库,第二,三方info级别日志文件
应用自身一般的日志文件
接口等重要日志文件(需要监控)
任务日志文件
其他特殊日志文件
2.2 日志级别
JDK 标准的日志 API 使用的级别包括 OFF、SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST 和 ALL 等。
Log4j 使用的级别则包括 OFF、FATAL、ERROR、WARN、INFO、DEBUG、TRACE 和 ALL 等。
一般情况下,使用得比较多的级别是 FATAL、ERROR、WARN、INFO、DEBUG 和 TRACE 等。这 6 个级别所对应的情况也有所不同:
- FATAL(致命):严重的错误,系统无法正常运行,如硬盘空间满等。该日志级别必须慎用,一个进程的生命周期中应该只记录一次FATAL级别的日志。
当然,如果某个系统的子系统遇到了不可恢复的错误,那该子系统的调用方也可以记入FATAL级别日志,以便通过日志报警提醒系统管理员修复;
- ERROR(错误):运行时异常以及预期之外的错误。需要马上被处理。这个级别用的较多,常常伴随Java异常,错误(Error)的环境不一定会造成系统的崩溃,已经影响了用户的正常访问,然而却无法提供正常的服 务。
特别需要注意的是,ERROR和FATAL都属于服务器自己的异常,是需要马上得到人工介入并处理的。而对于用户自己 操作不当,如请求参数错误等等,是绝对不应该记为ERROR日志的;
- WARN(警告):系统可以正常运行,但需要引起注意的警告信息,此种级别的日志也不应太多。这个级别预示较小的问题,包括那些目前还不是错误,然而不及时处理也会变为错误的情况。
举例:1,由系统外部的因素造成的,比如用户输入了不符合条件的参数。2,程序调用了一个即将作废的接口,接口的不当使用,运行状态不是期望的但仍可继续处理等。3,一个存储系统的磁盘使用量超过阀值,或者系统中某个用户的存储配额快用完等等。
- INFO(通知):系统运行的主要关键时点的操作信息,一般用于记录业务日志,记录了系统日常运转中有意义的事件。
通过查看INFO级别的日志,可以很快地对系统中出现的 WARN,ERROR,FATAL错误进行定位。INFO日志不宜过多,通常情况下,INFO级别的日志应该不大于TRACE日志的10%。举例:如程序启动,关闭事件,收到请求事件等。
- DEBUG(调试):这种日志具体的规范应该由项目组自己定义,该级别日志的主要作用是对系统每一步的运行状态进行精确的记录。关心程序操作(细粒度),不太关心业务操作(粗粒度)。
通过该种日志,可以查看某一个操作每一步的执行过程,可以准确定位是何种操作,何种参数,何种顺序导致了某种错误的发生。
- TRACE(跟踪):比DEBUG更加具体的详细信息。
在这 6 个级别中,以 ERROR、WARN、INFO 和 DEBUG 作为常用。
需要注意的是
- 一个项目各个log级别的定义应该是清楚明确的,是每个开发人员所遵循的;
- 系统出现问题时,必须抛出异常,在处理异常时记录日志,且日志级别必须是前三个级别(Fatal\Error\Warning)中的一种。
- 即使是TRACE或者DEBUG级别的日志,也应该有一定的规范,要保证除了开发人员自己以外,包括测试人员和运维人员都可以方便地通过日志定位问题。
- 优先级大于等于设定级别的日志信息才可以被输出。
- Java的日志框架一般会提供以下日志级别,缺省打开info级别,也就是debug,trace级别的日志在生产环境不会输出,在开发和测试环境可以通过不同的日志配置文件打开debug级别。
不同环境级别设置建议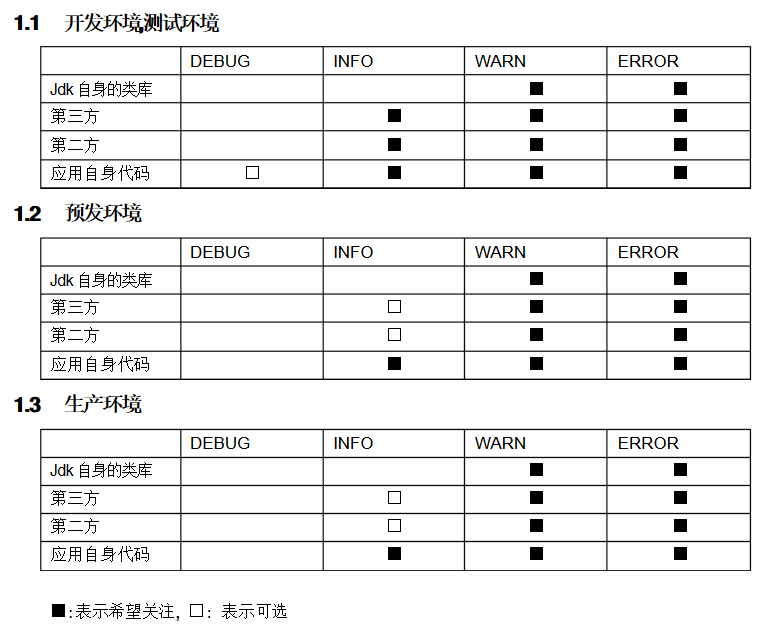
由于DEBUG日志量太大,因此通常线上只开INFO级别日志。然而INFO级别的 日志却有可能导致部分问题无法定位。
因此我们推荐的做法是,如果是多服务器系统,比如一个请求可能随机地分发到4台机器进行处理,因此如果某一种错误在一段时间内多次出现,它也会在4台服务器 上都出现。选择一台机器开启DEBUG级别的日志,方便定位问题。其实该做法背后的目的是,在线上任何问题的时候,都可以通过日志最快的找到问题的根源。
备注:在一些大型系统中,会需要更细化的分级和模块描述,这些系统对模块和日志级别的划分会参考Syslog标准协议进行设计
2.3 日志命名规范
根日志(root logger)位于日志层次的最顶层,它的日志级别不能指派为空;不能通过使用它的名字直接得到它,而应该通过类的静态方法Logger.getRootLogger得到它(指root logger)。所有其他的日志可通过静态方法Logger.getLogger来实例化并获取,这个方法Logger.getLogger把所想要的logger的名字作为参数,一般取本类的名字作为参数。
2.4 日志配置规范
所有的日志配置文件放在src目录下,编译时随同.class文件一同拷贝到(%webapp_HOME%)\WEB-INF\classes\目录下,这些配置文件必须采用properties文件的编写方法, commons-logging.properties文件用来指定commons-logging的实现为log4j,log4j.properties文件用来配置log4j的所有参数,日志配置信息不得配置在这两个文件以外的文件中。
2.5 多线程支持规范
方式一:log4j NDC
日志记录必须支持多线程。当应用程序同时处理多个客户的请求时,不同客户之间的日志信息写同一个日志文件时不应产生冲突,不同请求的日志信息能被显示并区分出来。在应用系统中,必须使用log4j NDC(Nested Diagnostic Contexts)来处理多线程的日志记录。当程序响应请求时,通过Log4J NDC(Nested Diagnostic Contexts)机制,将日志(logger)推入栈中,当程序完成处理或抛出异常时,NDC弹栈,以保证同一线程日志的一致性。但是NDC还是建议配合RequestID这种方式关联上下文。
方式二:log4j MDC
MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 和 logback 提供的一种方便在多线程条件下记录日志的功能。某些应用程序采用多线程的方式来处理多个用户的请求。在一个用户的使用过程中,可能有多个不同的线程来进行 处理。典型的例子是 Web 应用服务器。当用户访问某个页面时,应用服务器可能会创建一个新的线程来处理该请求,也可能从线程池中复用已有的线程。在一个用户的会话存续期间,可能有 多个线程处理过该用户的请求。这使得比较难以区分不同用户所对应的日志。当需要追踪某个用户在系统中的相关日志记录时,就会变得很麻烦。
一种解决的办法是采用自定义的日志格式,把用户的信息采用某种方式编码在日志记录中。这种方式的问题在于要求在每个使用日志记录器的类中,都可以访问到用户相关的信息。这样才可能在记录日志时使用。这样的条件通常是比较难以满足的。MDC 的作用是解决这个问题。
MDC 可以看成是一个与当前线程绑定的哈希表,可以往其中添加键值对。MDC 中包含的内容可以被同一线程中执行的代码所访问。当前线程的子线程会继承其父线程中的 MDC 的内容。当需要记录日志时,只需要从 MDC 中获取所需的信息即可。MDC 的内容则由程序在适当的时候保存进去。对于一个 Web 应用来说,通常是在请求被处理的最开始保存这些数据。
2.6 日志输出规范
禁止使用JDK Console输出
禁止使用JDK Console输出(System.out, System.err, ex.printStackTrace(), etc.)。所有的日志实例的属性都应从根日志(root logger)继承。日志信息必须支持输出到控制台(console)和文本文件(TextFiles)。
日志文件不宜过大
过大的日志文件对于日志监控,问题定位等都会带来不便。因此需要进行日志文件的切分,日志文件的切分可以通过log4j等日志工具来配置,日志文件应该按天来分割,还是按照小时来分割,应该根据日志量来决定,原则就是方便开发或运维人员能快速查找日志。
日志文件名必须满足统一命名规则
举例:即日志文件名必须满足<系统名称>.log.yyyyMMddHH的命名规则。yyyyMMddHH表示每日整点时重新命名日志文件,以方便按时间定位日志信息;文件大小限制为最多20Mb,即当日志文件超过20Mb时,旧日志文件重命名为<系统名称>.log.yyyyMMddHH.n(n从1开始编号以步长1递增),新日志写入<系统名称>.log.yyyyMMddHH。这里的<系统名称>表示各个实际项目的英文缩写,英文缩写必须遵循单位对系统英文缩写的统一规定。
特殊情况:并发量很大时
对于并发量很大时,可能会有一些请求处理失败(如0.5%),为了对这些错误进行分析,需要去查这些错误请求的日志。而由于这种情况下并发量很大,使得对错误日志的分析变得困难。这种情况下可以将所有的错误日志同时输出到一个单独的文件之中。
2.7 日志内容规范
“敏感”信息不记录
对于“敏感”的单位信息,如客户密码、余额等信息,禁止使用debug以上级别的日志方法记录,在开发过程中,也应减少日志对该类信息的记录,以防止日志文件不慎外泄时保全用户的数据安全;日志通常不允许修改,必要时还可以通过校验位来鉴别日志是否正确。
异常(Exception)全记录
所有的异常(Exception)都必须写在日志中,当系统抛出异常时,除了使用log.error()记录定制信息外,还必须打印异常树信息,例如log.error(定制信息, e)。
定义好整个团队记录DEBUG(或TRACE)日志的规范,保证每个开发记录的日志格式统一;
例如:
日志的输出格式(不包括异常树信息)规定如下:
日期(yyyy-M-d) 时间(HH:mm:ss) NDC标志[级别](对应程序文件名:行号)定制信息。
即,%d{yyyy-M-d HH:mm:ss}%x[%5p](%F:%L) %m%n
- 对于Info级别的信息,建议使用半结构化的日志消息
|
|
当需要通过日志记录来排查某个用户所遇到的问题时,只需要通过正则表达就可以很快地查询到用户相关的日志记录。
哪些是有意义的日志
通常情况下在程序日志里记录一些比较有意义的状态数据:
- 程序启动,退出的时间点;
- 程序运行消耗时间;
- 耗时程序的执行进度,不然程序开始运行后半天没一点输出挺让人着急啊~
- 重要变量的状态变化。
日志记录信息要完整
日志信息要准确全面,能做到仅凭日志就可以定位问题,整理所有的请求处理流程,针对每一个操作(去重,分块上传……)打印特定的日志。记录系列操作的关联信息,方便查找跟踪操作。比如记录RequestID,在RequestID中尽量编码更多的信息,将一个请求的整个处理流程和唯一的requestID关联起来。
推荐的需要在日志中记录的内容有:
在系统启动或初始化时记录重要的系统初始化参数
记录系统运行过程中的所有的错误
记录系统运行过程中的所有的警告
在持久化数据修改时记录修改前和修改后的值
记录系统各主要模块之间的请求和响应(如视频处理模块在接收到请求和发送应答时,或者向客户端发送回调请求时)
重要的状态变化(如系统白名单的修改等)
系统中一些长期执行的任务的执行进度
而不推荐记录日志的内容有:
函数入口信息 —— 除非该函数入口表示了一个重要事件的开始,或者将该信息记入DEBUG级别日志
文件内容或者一大段消息的内容 —— 如果实在需要记录,则可以截取其中一些重要的信息来记入日志
“良性”错误 —— 有时候虽然出现了错误,然而错误处理的流程可以正确解决这种情况,例如插入数据库时有重复的记录,尽管是个错误,然而错误处理流程可以对这种情况进行处理
2.8 日志编写规范
各种常用级别的使用示例:
|
|
日志格式要统一规范
日志格式一定要统一,不能任由开发人员的喜好来。举例来说,对于NOS视频截图超时的ERROR日志,有以下几种方式打印:
第一种:
|
|
第二种:
|
|
第三种:
|
|
第一种方式打印日志即是开发人员按照自己的喜好来的,这种方法带来的问题是:
系统中日志格式不统一,不利于自动化处理
有些日志可能只有开发人员自己才能看懂
代码规范性不好
而第三种方式,通过一个函数来规范日志格式,所有开发人员便可以通过该接口实现统一的日志。
调用DEBUG时,必须判断DEBUG级别是否生效
为了防止因特殊情况需要关闭所有系统日志,而引起系统性能急剧下降。要在调用DEBUG时,必须判断DEBUG级别是否生效,其他级别无需判断。如直接调用log.debug(tmpString)是错误的,必须采用以下方法处理DEBUG级别的日志:
|
|
但更好的方法是Slf4j提供的最佳实践:
|
|
一方面可以减少参数构造的开销,另一方面也不用多写两行代码;
禁止一些结构复杂的对象被直接放入日志中作字符串处理
在输出日志之前完成字符串操作,禁止一些结构复杂的对象被直接放入日志中作字符串处理。如下方式的日志记录方法是不正确的:
|
|
这种调用方式会引起过多的构建信息参数的花费。定制信息的组合必须在输出日志之前完成字符串的操作,可使用StringBuffer提高效率。
同样建议不要把toString()方法用在访问具有许多方法并生成大串的复杂对象上。(也可以给这种日志输出定义一个低优先级的输出级别)。
绝不要打印没有用的日志,防止无用日志淹没重要信息
不要在循环中记录日志,比如在会反复执行的操作中记录同样的信息。
例子:
|
|
如果readData抛异常,并且hasNext方法返回true,最终我们无限记录日志。解决它的一个方法是确保我们不记录所有东西:
|
|
另一个方式是把日志从循环中完全移除,并且保存第一个或最后一个异常对象到其他地方记录。
- Error级别以下的日志不建议显示生成日志输出的那个类、方法和行号(Log4j提供此功能,该设置在生产中应该被关闭,因为生成这类信息的代价非常高。)。
通过日志级别的提升来发现潜在问题
举例:
在接收到一个请求的时候,会记录请求的接收时间(T1),在请求处理完成待发送的时候,会记录请求发送时间(T2),通常一个请求的日志都记 为INFO级别,然而当出现请求处理时间(T2-T1)超过一定时间(如10s)时,会将该日志提升为WARN级别。通过该方法,可以预先发现系统可能存 在的一些问题。
同样的慢操作日志还可以用来记录系统一些外部依赖的处理时间,如NOS依赖外部认证服务器来进行认证。我们会记录每个请求的认证时间,如果认证时间超过某个值,也需要将该事件的日志级别进行提升,这样我们可以尽早发现认证服务器是不是需要扩容等问题。
慢日志的时间阀值应该是可以动态调整的,这样在进行系统优化时,可以将该报警时间阀值逐渐调小,不断地对系统进行优化。
2.9 日志备份维护
监测
- 整个团队(包括开发,运维和测试)定期对记录的日志内容进行Review;
- 新上线服务器后一定要对日志进行观察,特别地,开发人员可以通过观察日志来确认新功能是否工作正常
- 对日志进行监控报警,比客户先发现系统问题
设置了日志监控报警,周期性的(1分钟,5分钟)对服务器新产生的日 志进行监控,如果发现错误数超过某个阀值,则进行报警。同时评估日志监控是否对服务产生影响
备份
- 为了防止日志文件将整个磁盘空间占满,需要定期对日志文件进行删除。例如,在收到磁盘报警时,可以将两个月以前的日志文件删除。此处比较好的实践是:
将所有日志文件收集起来,这样即使在记录日志的机器上删除,也可以通过收集的日志对之前的问题进行定位;
每天通过定时任务来删除过期日志,如每天在凌晨4点删除60天前的日志
- 为了防止日志文件将整个磁盘空间占满,需要定期对日志文件进行删除。例如,在收到磁盘报警时,可以将两个月以前的日志文件删除。此处比较好的实践是:
分析
- 通过日志中的关键字来确定系统的运行状态
- 做好日志聚合与分析参考Java 日志管理最佳实践 - IBM-成富
优化
- 从问题中完善日志,日志的优化是一件持续不断需要投入精力的事,需要不断从错误中学习(定位问题花费太多时间,是否需要优化来预判可能发生的问题)
- 需要定期对日志内容进行优化更新,目的就是通过日志快速准确的定位问题
3. Java 上的日志系统的实现技术
框架:
在java 中实现记录日志最初的方式,就是system.print.out ,err 这样直接在控制台打印消息,缺点太多了,这样与业务逻辑无关的代码会变得更多,不能按日志等及输出,以及那些不输出等。
所以出现了一些日志框架,之后还有一类实现日志统一的框架用来封装不同的日志框架,常用如下:
日志框架:
- JUL,java util logging在jdk的java.util.logging包中,也叫jkdLog或者jdk14log; 在JDK 1.4 版本之后,java提供了日志的API ,可以往文件中写日志了,最方便不需要第三方包,其实际使用人较少。
- log4j ,准确的说是log4j 1.x版。Apache的开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;用户也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,用户能够更加细致地控制日志的生成过程。这些可以通过一个配置文件(XML或Properties文件)来灵活地进行配置,而不需要修改程序代码。但是基于老的jdk性能不高,该项目现在已经停止维护,但是用的人还是最多的。
- Logback - Logback是由log4j创始人设计的又一个开源日记组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个改良版本。此外logback-classic完整实现SLF4J API使你可以很方便地更换成其它日记系统如log4j或JDK14 Logging;
- Log4j2 (这里主要指log4j-core部分,框架接口实现)该项目是log4j的升级版,性能较好,也吸收了Logback等日志记录组件的优点。包含了基于LMAX 分离库的下一代的异步日志系统,在多线程环境下,异步日志系统比 Log4j 1.x 和Logback 提高了10倍性能提升(吞吐量和延迟率 )
实现日志统一的框架
- Apache Commons Logging是一个日志接口,通过动态查找的机制,在程序运行时自动找出真正使用的日志库。最综合和常见的日志记录方式, 经常是和log4j或者log4j2 结合起来使用。曾经最为流行。
- Slf4j为各种Logging API提供一个简单统一的接口,在编译时静态绑定真正的Log库,从而使用户能够在部署的时候配置自己希望的Logging API实现,支持参数化的log字符串,现在比较流行,最常见的是和Logback一起使用。
- Log4j2 (这里主要指log4j-api部分)框架接口层,目前还主要是和框架自身的实现层一同使用。
使用场景:
- 小项目:直接使用log4j或Logback,新开发的渐渐换成了log4j2
- 旧项目:Apache Commons Logging + log4j
- 新项目:Slf4j + Logback
- 框架项目:Slf4j
- 最新、迭代项目:log4j2
由于log4j2吸收了Logback等日志记录组件的优点,在多线程环境下性能优势明显,版本上也已经推出2.6.2,所以选择log4j2成了现今项目的首选。
实际开发中,可能还需要考虑到项目中其他框架所使用的日志库来考虑需要使用的项目日志框架,或者习惯使用Slf4j的参数化log字符串功能,则会使用Slf4j + log4j2,但是log4j2是不推荐的,因为会影响性能。
4. 评估具体实现技术的选型与原因
slf4j 与 common-logging 比较
common-logging通过动态查找的机制,在程序运行时自动找出真正使用的日志库。由于它使用了ClassLoader寻找和载入底层的日志库, 在程序运行时自动找出真正使用的日志库。common-logging内部有一个Simple logger的简单实现,但是功能很弱。所以使用common-logging,通常都是配合着log4j来使用。使用它的好处就是,代码依赖是common-logging而非log4j, 避免了和具体的日志方案直接耦合,在有必要时,可以更改日志实现的第三方库。只要引入了log4j 并在classpath 配置了log4j.xml ,则commons-logging 就会使log4j 使用正常,而代码里不需要依赖任何log4j 的代码。因为OSGI的不同的插件使用自己的ClassLoader。 OSGI的这种机制保证了插件互相独立,然而却使Apache Common-Logging无法工作。
slf4j全称为Simple Logging Facade for JAVA,java简单日志门面。类似于Apache Common-Logging,是对不同日志框架提供的一个门面封装,可以在部署的时候不修改任何配置即可接入一种日志实现方案。但是,他在编译时静态绑定真正的Log库。使用SLF4J时,如果你需要使用某一种日志实现,那么你必须选择正确的SLF4J的jar包的集合(各种桥接包)。另外,SLF4J 支持参数化的log字符串,避免了之前为了减少字符串拼接的性能损耗而不得不写的if(logger.isDebugEnable()),现在你可以直接写:logger.debug(“current user is: {}”, user)。拼装消息被推迟到了它能够确定是不是要显示这条消息的时候,但是获取参数的代价并没有幸免。
不过当程序规模越来越庞大时,JCL的动态绑定并不是总能成功,具体原因大家可以 Google 一下,这里就不再赘述了。解决方法之一就是在程序部署时静态绑定指定的日志工具,这就是 SLF4J 产生的原因。
可见,在配置上common-logging是更便捷的,但其动态绑定库,也使部分第三方库无法使用。slf4j则在性能和配置灵活性上更有优势。
Log4j 与 LogBack 比较
LogBack作为一个通用可靠、快速灵活的日志框架,将作为Log4j的替代和SLF4J组成新的日志系统的完整实现。
LOGBack声称具有极佳的性能,“某些关键操作,比如判定是否记录一条日志语句的操作,其性能得到了显著的提高。这个操作在LogBack中需要3纳秒,而在Log4J中则需要30纳秒。 LogBack创建记录器(logger)的速度也更快:13微秒,而在Log4J中需要23微秒。更重要的是,它获取已存在的记录器只需94纳秒,而 Log4J需要2234纳秒,时间减少到了1/23。跟JUL相比的性能提高也是显著的”。 另外,LogBack的所有文档是全面免费提供的,不象Log4J那样只提供部分免费文档而需要用户去购买付费文档。
LogBack相对与Log4j还有其他方面的优势,如:
- logback-classic 非常自然的实现了SLF4J
- 自动重新载入配置文件 ,扫描过程很快,无资源争用
- 优雅地从I/O错误中恢复,保证日志功能正常工作。
- 自动清除旧的日志归档文件。
- 自动压缩归档日志文件,压缩通常是异步执行的。
- 谨慎模式,在多个JVM中运行的多个FileAppender实例,可以安全的写入统一个日志文件。
- Lilith处理大量记录和访问事件查看器。
- 配置文件中的条件处理,同一个配置文件就可以在不同的环境中。
- Logback拥有远比log4j更丰富的过滤能力,例如某个用户以DEBUG级别被记录,而其他用户仍然是以WARN级别来记录日志。
- SiftingAppender是一个全能的追加器,基于任何给定的实时属性分开(或者筛选)日志。
- 堆栈轨迹信息包含包的数据。
- Logback-access模块,提供了通过HTTP访问日志的能力,是logback不可或缺的组成部分。
备注:详细说明参见从Log4j迁移到LogBack的理由
为何选择Log4j2
首先,log4j2相对于log4j 1.x有了脱胎换骨的变化,不仅仅是log4j的简单升级,而是整个项目的重构。
Log4j 1.x 在高并发情况下出现死锁导致cpu使用率异常飙升,而Log4j2.0基于LMAX Disruptor的异步日志,在多线程环境下,性能会远远优于Log4j 1.x和logback(官方数据是10倍以上吞吐量和延迟率),以及可配置的审计型日志、基于插件架构的各种灵活配置等。
其次,log4j、logback、log4j2均出自同一作者,而他们之间的关系就是替代。Slf4j也是这一作者,Slf4j是为了替代Apache Commons Logging。而在最新log4j2上,作者并不建议Slf4j+log4j2,因为影响log4j2性能。
作者针对性能做了专门介绍: 决定日志系统好坏的一个重要参数就是它的性能指标。这很重要,因为即使一个中等规模的应用程序每秒产生的日志都数以千计。我们花费了大量精力在测量和调整 log4j 2 的性能。 log4j 声称,日志框架应该很快,并且要求灵活:速度第一,灵活性第二。
Log4j2优势
- Log4j 2被设计成对安全审计有用的日志框架。在Logback框架中,当输出日志产生异常时,从来不会告诉被调用方,而log4j 2,这个将是可配置的。
- Log4j 2使用了新一代的基于LMAX Disruptor的无锁异步日志系统。在多线程的程序中,异步日志系统吞吐量比Log4j 1.x和logback高10倍,而时间延迟却更低。
- Log4j 2使用插件机制,更灵活。扩展appenders,Filters,Layouts,Lookups和Pattern Converters将变得更加简单,而不用去更改任何Log4j本身。
- 因为插件机制,在配置文件中,不再需要指定定制的类名称。
- 消息对象的支持。消息允许对有趣的和复杂的结构的支持,并通过日志记录系统,有效地操纵。用户可以创建自己的消息类型和编写自定义布局,过滤和查找操作。
- Log4j 1.x支持在Appenders上的过滤器。Logback通过添加turbofilters允许Logger在处理之前过滤事件。Log4j 2则支持在Logger处理之前配置处理事件过滤器,效果和被Logger或Appender处理一样。
- Logback Appenders 不支持布局,只支持一个固定格式。 Log4j2 Appenders 支持布局,可以实现任何格式要求的数据传送。
- 布局在 Log4j 1.x 和 Logback 返回的是一个字符串。这导致了在Logback编码上的一个问题。Log4j 2以更简单的方法,布局始终返回一个字节数组。这样意味着可以用在任何Appender,不只是写到一个输出流。
- Syslog Appender 同时支持 TCP 和 UDP ,以及 BSD syslog 和 RFC 5424 格式的支持.
- Log4j 2在底层尽可能使用了Java5提供的对并发及锁支持的工具类。Lo4j 1.x有死锁的bug。Logback中修复了log4j 1.x的很多bug,但是,logback中的有很多类采用同步机制(这种机制导致性能下降)。
可见Log4j2不仅仅是Log4j的升级,同时兼具了Logback特性,并有所增强。而且同时提供了接口和实现,对后期扩展的支持也是比较好的。
5. Log4j2 详解及Demo
基础配置
添加jar包
|
|
测试代码
|
|
|
|
运行后输出
|
|
可以看到log4j2先发了一句牢骚,抱怨没有找到配置文件什么的,从我们实验的结果可以看出,log4j默认的优先级为ERROR或者WARN(实际上是ERROR)。
首先需要注意的是,log4j 2.0与以往的1.x有一个明显的不同,其配置文件只能采用.xml, .json或者 .jsn。在默认情况下,系统选择configuration文件的优先级如下:(intellij项目中为resources文件夹)
classpath下名为 log4j-test.json 或者log4j-test.jsn文件
classpath下名为 log4j2-test.xml
classpath下名为 log4j.json 或者log4j.jsn文件
classpath下名为 log4j2.xml
必须注意.xml 文件的文件名为log4j2,这里让我纠结了一个下午,系统一直找不到配置文件,最后发现是文件名里面少了一个2。
如果都没有找到,则会按默认配置输出,也就是输出到控制台。
下面是log4j2的
我们按默认配置添加一个log4j2.xml,添加到src根目录即可
|
|
重新执行测试代码,可以看到输出结果相同,但是没有再提示找不到配置文件。
配置说明:
|
|
如果把level改为trace,可以看到控制台除了输出调试信息,还输出了
|
|
自定义Logger
当在Loggers中配置成(Root的level为error):
|
|
输出结果:
|
|
可以发现,当只配置一个Root时,Log4j2Test和MyApplication的logger都是按Root的配置输出;而当配置name=”com.feibo.log4j2demo.MyApplication”的Logger后,MyApplication则按这个新配置输出。
原因在于MyApplication中Logger logger = LogManager.getLogger(MyApplication.class.getName())。
所以Loggers是用来配置指定Logger的输出配置的,如果没指定则会按Root的配置输出。如果不配置Root,则会读取默认的Root配置。
additivity=”false”表示在该logger中输出的日志不会再延伸到父层logger。这里如果改为true,则会延伸到Root Logger,遵循Root Logger的配置也输出一次。
说明:本例中设置为true,MyApplication的log会被打印两次,第二次打印是按照root里面定义的AppenderRef进行输出。
appender-ref必须为先前定义的appenders的名称,可配置多个。例如,此处为Console。那么log就会以appender所定义的输出格式来输出log。
自定义Appender
修改配置文件,添加一个文件类型的Appender,并且把MyApplication的AppenderRef改为新加的Appender
|
|
可以看到项目根目录下输出了app.log文件,记录了MyApplication的log。
同时控制台输出:
|
|
MyApplication的logger的AppenderRef只配置了MyFile,但是additivity设置为true,所以控制台上也输出了。
如果MyApplication配置如下,输出结果和上面一样:
|
|
RollingRandomAccessFile和properties
RollingRandomAccessFile 是用来配置一个按时间和文件大小滚动的Appender,相比RollingFileAppender有很大的性能提升,官网宣称是20-200%。
Rolling的意思是当满足一定条件后,就重命名原日志文件用于备份,并从新生成一个新的日志文件。例如需求是每天生成一个日志文件,但是如果一天内的日志文件体积已经超过1G,就从新生成,两个条件满足一个即可。这在log4j 1.x原生功能中无法实现,在log4j2中就很简单了。
xml配置修改如下:
Configuration下增加:
|
|
|
|
|
|
修改MyApplication的doIt()代码,模拟文件体积超过10M和时间超过1分钟来验证结果:
|
|
结果可以看到自动输出到指定文件夹并转移和分包。
自定义配置文件位置
log4j2默认在classpath(Intellij下是resources)下查找配置文件,可以修改配置文件的位置。在非web项目中:
|
|
如果是web项目,在web.xml中添加
|
|
高级配置
按日志级别区分文件输出
按日志信息级别输出到不同名称的文件中,如info.log,error.log,warn.log等,在log4j2中可通过配置Filters来实现。
看配置注释:
|
|
添加过滤器Filter,一是在配置文件的
* ThresholdFilter 用来过滤指定优先级的事件。
* TimeFilter 设置start和end,来指定接收日志信息的时间区间。
<TimeFilter start="05:00:00" end="05:30:00" onMatch=" NEUTRAL " onMismatch="DENY"/>
* RegexFilter 正则表达式过滤器
<RegexFilter regex=".* test .*" onMatch="NEUTRAL" onMismatch="DENY"/>
onMatch和onMismatch可以选择的值及其含义。可选的值分别是,ACCEPT, DENY, NEUTRAL,ACCEP和DENY比较好理解就是接受和拒绝的意思,在使用单个过滤器的时候,一般就是使用这两个值。但是在组合过滤器中,如果用接受ACCEPT的话,日志信息就会直接写入日志文件,后续的过滤器不再进行过滤。所以,在组合过滤器中,接受使用NEUTRAL(中立),被第一个过滤器接受的日志信息,会继续用后面的过滤器进行过滤,只有符合所有过滤器条件的日志信息,才会被最终写入日志文件。
异步写日志
官方建议一般程序员查看的日志改成异步方式,一些运营日志改成同步。线程越多性能提高越明显。
异步方式有Asynchronous Appenders 和 Asynchronous Loggers,区别是Asynchronous Appenders 性能比同步快,但比Asynchronous Loggers慢。
Asynchronous Appenders
配置文件,看注释部分:
|
|
Asynchronous Loggers
因为logger async 用的是无锁并发技术,所以使用log4j2的AsyncRoot或AsyncLogger必须引入Disruptor
|
|
在loggers节点添加
|
|
或者添加
|
|
注意:有一博客提示开启异步需要在JVM启动参数中增加
-DLog4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
经测试貌似不用,如果未能开启,可设置试试。
其他输出到日志查看框架可以参考:
详解log4j2(下) - Async/MongoDB/Flume Appender 按日志级别区分文件输出
Web相关配置
- jar包:
除了非web项目的core和api包,还需要引入log4j-web
- web.xml配置
|
|
- log4j2.xml中第三方框架日志设置
|
|
如果遇到在IDE下一切运行正常,如果把应用打包成jar包发布后,cmd命令行模式下,即使Console开着的情况下,也没法输出,文件输出也没有任何日志。可参考Log4j2使用总结
全局未捕获异常配置
Web项目参考:
Spring3.0中的异常处理配置方法
利用Spring进行统一异常处理的两种方式
非Web项目参考:
Android自定义捕获Application全局异常
技巧
有时候,为了同一份log4j文件要支持写到不同的log中(否则会导致打印的内容被覆盖,其中一个进程写不进log等问题),需要在载入的时候对内容进行动态修改,比如根据server id分别生成game1.log,game2.log。这里应该是指根据正则过滤?
MDC使用
(介绍清看前文)
Log4j2的MDC使用方式
log4j2的MDC应用配置说明:经测试配置DynamicThresholdFilter或ThreadContextMapFilter都可以实现过滤,差别在于DynamicThresholdFilter可以配置级别,ThreadContextMapFilter未配置。同时发现Configuration下的全局Filter似乎不其作用?见本文末尾。
6. 在 Airplan 系统中的实现
(未开始)
参考文档
为什么需要日志审计系统
alibaba/BeautifulCode 日志
某大型银行深化系统之十九:日志规范
王健:最佳日志实践
Java 日志管理最佳实践 - IBM-成富
系统开发log日志使用规范
日志记录与异常处理规范
五个改善你服务器日志的技术
跨过slf4j和logback,直接晋级log4j 2
java日志组件介绍(common-logging,log4j,slf4j,logback )
从Log4j迁移到LogBack的理由
Java Log 系统介绍以及切换
Java日志相关记录 (Jul jcl log4j log4j2 Logback SLF4J)_带配置及简单使用源码
jdk-logging、log4j、logback日志介绍及原理
commons-logging与jdk-logging、log4j1、log4j2、logback的集成原理
slf4j与jdk-logging、log4j1、log4j2、logback的集成原理
slf4j、jcl、jul、log4j1、log4j2、logback大总结_日志系统之间的切换
详解log4j2(上) - 从基础到实战
详解log4j2(下) - Async/MongoDB/Flume Appender 按日志级别区分文件输出
log4j2 使用详解
log4j2 配置详解及使用范例
Log4j2 配置笔记(Eclipse+maven+SpringMVC)
Log4j2介绍和特性实例(四)–过滤器Filter
log4j2 与 spring mvc整合
使用slf4j + Log4j2构建日志
Log4j2使用总结
灵活控制 Hibernate 的日志或 SQL 输出,以便于诊断
log4j2的MDC应用配置
发现问题:
1、Configuration下的全局Filter似乎不其作用?
如增加
|
|
并未影响输出。

